Why we decided to move over eleven billion records from the legacy system
The legacy vehicle history database is a distributed key value store on OpenVMS. Compressed the database is roughly nine terabytes. This system has served CARFAX very well since 1984 when the company was founded, but we were capping on the number of reports per second that could be delivered per production cluster. The hardware cost and technical difficulties of scaling the legacy system were very high. Thus we decided to start looking at different options.
Why we decided to use MongoDB
As an Agile and extreme programming development shop, CARFAX uses Friday afternoons as professional/personal development time. Several developers began using this time to experimenting with traditional RDBMS and NoSQL solutions for the vehicle history database. The complexity of the data structures compounded with the size of the database did not lend itself to Oracle or MySql. We also evaluated Cassandra, CouchDB, Riak, and several other NoSQL solutions (I really wanted to use Neo4J to create a social network of cars). In the end we decided that MongoDB gave us the best of where we wanted to be in the CAP theorem and offered the level of commercial support we were looking for.
Challenges we faced during the migration
Cleansing, transforming, and inserting eleven billion complex records into a database is no small task. To avoid inconsistencies with the ongoing data feeds it was decided that we needed to load the existing records into MongoDB in under fifteen days. The legacy records were of multiple formats that required specific interpretations. Many of the records were also inserted using PL/I data structures that have no direct mapping in Java or C and required bitmapping and other fun tricks. Once we wrote the Java and C JNI algorithms to transform the old records to the MongoDB format we began our loads.
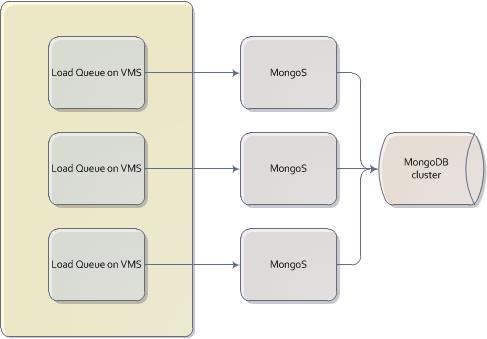
MongoDB does not support OpenVMS and as such we had to use remote MongoS processes to load the data. Using direct inserts to MongoDB we opened up the queues. The process was immediately computationally bound. The poor processers on the OpenVMS boxes were running full tilt; we could barely even get a command prompt to check on the system. We managed to throttle back the queues so we could get a stable session, but the projected extract, transform, and load time was at forty five days. We let the loads continue but we went back to the drawing board to consider how to solve the computational limitations we had hit.
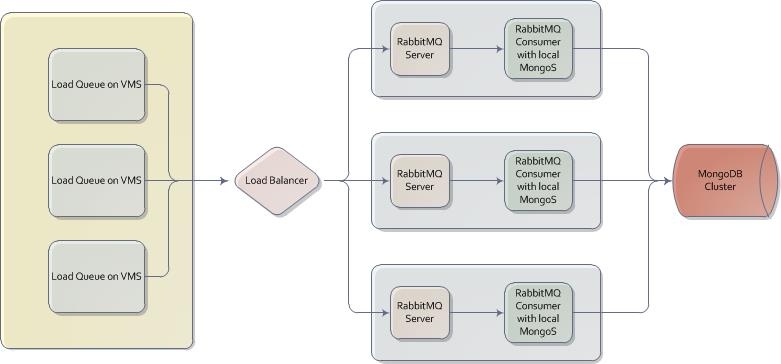
The Solution
The transformation and insertion logic was already pretty clean and stateless so with a modest amount work we were able to implement a multi-threaded
and multi-JVM RabbitMQ solution. We had some servers that were slated to become app-servers that were not being used yet so we deployed the RabbitMQ
servers and lots of consumer process onto them. We released the queues. The initial numbers did not look all that promising, but once the shard
ranges on MongoDB settled in we began to see very impressive load numbers. We averaged over eleven thousand plus writes a second to MongoDB.
We finished the load in just under ten days. Through judicious use of compression of certain fields that are not useful for normal queries or
aggregation the MongoDB collection was actually slightly smaller than the original database on OpenVMS.
Successes of the Migration
- Each replica set in the production cluster is capable of producing an order of magnitude more reports per second than the old system.
- They legacy system could only answer one question easily: What are the records for a given vehicle? Any others queries required a custom C crawler and could take weeks return the answers. In MongoDB we are able to product many useful reports from the data much faster.
- Setting up a new cluster in the legacy system was an extensive process. We can stand up a new replica set in MongoDB in about two days. This is only possible through the use of automation. Automate EVERYTHING.
- Cross datacenter data publication and synchronization was error prone and complicated under the old system. In MongoDB we are generally only a few seconds behind in our various data centers.
</ul>
Other Thoughts:
- If you are using a Linux distribution; check that you are not using the default ulimit settings! We suffered a massive cascading crash due to missing this in our initial automation settings.
- Moving terabytes of data though an internal network is a challenge. Work very closely with your network team to make sure everyone is ready for the traffic.
- Naming conventions for the fields in your MongoDB schema are very important! Due to the BSON format, remember that every character counts in large implementations.
- Consider your shard keys very carefully! Indexes on extensive collections use a lot of RAM. We chose a shard key that maximized read and write performance but it was not the _id field. This forced us into a two index situation. The _id index is only used for updates and deletes which are relatively infrequent in this system.
- If you are computationally bound, figure out how to grid out the problem. RabbitMQ worked well in our case, but carefully consider your problem domain and figure out what is the best solution. We also considered 0MQ and GridGain either would have been great choices but we decided upon RabbitMQ mostly due to in-house knowledge. We are currently evaluating moving our distributed load process to Scala and Akka.
- For high volume inserts the more shards the better (and LOTS of RAM)! Managing those shards can be tricky but it pays off.
- We attempted at one point to break the dataset down into a massive number of collections due to the collection level locking in MongoDB, however, the rebalancing of so many collections destroyed our ability to insert and we reverted back to a single large collection.
- In a large sharded collection make sure that queries that need to return quickly use the shard key. Otherwise you are forced into a scatter/gather query.
- The project was ultimately only a success due the amazing team at Carfax. If you love data and are looking for an excellent career opportunity we are always looking for good people to join us. </ul> A special thanks goes out to Brendan McAdams (@rit on Twitter) for helping us in our initial development phase! Here is a link to the official Carfax statement on the migration to MongoDB: http://www.mongodb.com/press/carfax-selects-mongodb-power-11-billion-record-database
About Me
Jai Hirsch
Senior Systems Architect
CARFAX
jai.hirsch@gmail.com